上一篇文章我們使用不需要寫程式的強大平台 - FlowiseAI 來建造一個 AI 團隊,將一系列需要人工然後又很繁瑣的事交給 AI 順利的完成。那這次鐵人賽最重要的幾個技術實作過了,也有用 NoCode 的工具實作了一樣的技術,倒數第二天就來分享一下在搜集資料時一些好用的解析工具吧。
Whisper 這個工具已經推出好一段時間了,大家應該都不陌生,可能也都很熟。我自己有拿 Whisper 做很多很有趣的事情,像是用說話的方式跟 AI 聊天,AI 的回覆也會是聲音;或者是將 React 跟 Whisper 串接,透過講話的方式來改變網頁的配置或配色。但這些東西都不僅僅只有用到 Whisper,所以我今天將回歸原始用 Whisper 解析並摘要李宏毅教授的 【生成式AI導論 2024】第9講:以大型語言模型打造的AI Agent (14:50 教你怎麼打造芙莉蓮一級魔法使考試中出現的泥人哥列姆) 這部影片,因為我對於 10 分鐘以上的影片真的覺得很長🤣
Whisper GitHub 有提供說明如何安裝,那我自己以安裝套件的方式不成功,所以會直接抓 Whisper GitHub 的版本來使用。
# 這個方式我無法安裝成功,會出現 triton 套件的錯誤
# pip install -U openai-whisper
# 我是使用這個方式安裝
pip install git+https://github.com/openai/whisper.git
poetry add git+https://github.com/openai/whisper.git
安裝好套件之後,還需要安裝一個叫 ffmpeg 的工具。依照自己的電腦來選擇安裝的方式,我自己是 Mac 所以用 Homebrew 安裝,Colab 的話是使用第一個來安裝喔~
# on Ubuntu or Debian
sudo apt update && sudo apt install ffmpeg
# on Arch Linux
sudo pacman -S ffmpeg
# on MacOS using Homebrew (https://brew.sh/)
brew install ffmpeg
# on Windows using Chocolatey (https://chocolatey.org/)
choco install ffmpeg
# on Windows using Scoop (https://scoop.sh/)
scoop install ffmpeg
接下來就來將影片轉換成逐字稿吧!那可以使用 whisper 的這個套件當然是沒問題,但我發現他沒辦法用 Mac 的 GPU 跑,所以想說換成 transformers 的,但是一直噴錯寫說不支援 mps,所以我只好就算了,還是乖乖摸摸鼻子用 Colab 的 Cuda 吧,速度是快蠻多的🤣
# 匯入套件
import whisper
# 檔名
file = "李弘毅教授講AI_Agent.mp4"
# 載入 whisper medium 的模型
model = whisper.load_model('medium')
# 開始轉成逐字稿,verbose=True 可以看 whisper 的解析過程
result = model.transcribe(file, verbose=True)['text']
# 逐字稿匯出成 txt 檔
with open('李弘毅教授講AI_Agent.txt', 'w') as f:
f.write(result)
要直接進行摘要當然也是可以,但是當如果今天的內容太長的話,沒辦法一次性的餵給模型,但當然目前像是 GPT-4o 或 Claude 3.5 都可以吃很長的長度。但假如今天我們使用的模型沒辦法接收這麼大量的資料,就需要進行 Map-Reduce 來處理,那 Map-Reduce 是什麼呢?簡單解釋一下:
Map 函數,該函數接收輸入數據並轉換為一系列的鍵值對(key-value pairs)。這些鍵值對用於進一步處理或聚合。以長文本摘要舉例的話,那就是會先將原文切割成更小的內容,然後對其一一進行摘要。Reduce 函數進行計算。這個函數通常會對這些值進行聚合操作,如求和、平均、計數等。例如,在上面長文本摘要的例子中,Reduce 階段會將每一小部分的摘要結果進行合併,並且再重新摘要一次,Reduce 的輸出通常是最終結果。# 匯入套件 & 選擇模型
from langchain_ffm import ChatFormosaFoundationModel
from langchain.prompts import PromptTemplate
from langchain_text_splitters import RecursiveCharacterTextSplitter
import threading
llm = ChatFormosaFoundationModel()
# 讀取 txt 檔
with open("李弘毅教授講AI_Agent.txt", 'r') as f:
text = f.read()
# 切割文本
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
documents = text_splitter.create_documents([text])
# map 函數
def map_summary(index, content, results, failed_indices):
try:
prompt = PromptTemplate.from_template("請將以下內容進行摘要: {text}")
chain = prompt | llm
summary = chain.invoke(content).content
results[index] = summary
except Exception as e:
failed_indices.append(index)
print(f"Error processing document {index}: {e}")
# 使用 map 函數進行平行運算
def process_documents(documents):
results = [None] * len(documents)
failed_indices = []
threads = []
for i, doc in enumerate(documents):
t = threading.Thread(target=map_summary, args=(i, doc, results, failed_indices))
t.start()
threads.append(t)
for t in threads:
t.join()
return results, failed_indices
# 取得 map 結果並且合併
results, failed_indices = process_documents(documents)
map_result = '\n'.join(results)
# reduce 函數
def reduce_summary(results):
prompt = PromptTemplate.from_template("請將以下內容進行摘要: {text}")
chain = prompt | llm
reduced_summary = chain.invoke(results).content
return reduced_summary
# 輸出最終結果
results = reduce_summary(map_result)
print(results)

程式碼結果探討 🧐:
pyannote.audio:這是一個專門用來處理語音訊號的開源套件,主要用來識別說話人。譬如說在一段對話中,他可以明確分出有幾個人在講話,然後針對每一句話標註說是哪個人說的。SpeechBrain:這是一個開源的語音處理框架,專門用來進行各種語音任務,如語音識別、語音合成、說話人識別、語言建模等。它是一個靈活且可擴展的工具包,旨在讓研究人員和開發者能夠輕鬆地構建和訓練語音處理模型。noisereduce:這是一個簡單而實用的音頻降噪工具,能有效提升你在語音處理任務中的音頻質量,並最終提高語音識別的準確性。不知道大家有沒有常處理到 PDF 檔案的時候,然後 Python 的所有套件解析出來的往往都很醜不好閱讀,那今天要使用的工具是 LlamaParse,他可以很完整的解析 PDF 的內容,然後將其轉換為 Markdown 或 txt 格式,整個內容就會變得很整齊很漂亮。LlamaParse 是一個很強大很專業的工具,他是由 LlamaIndex 所提供的工具,然後是開源的,只要到 LlamaCloud 註冊拿 API 即可使用他們的服務。那因為我只有拿來解析 PDF,所以我不知道 LlamaParse 其他的功能,但他解析 PDF 的結果是真的香啊!那一樣我們實作要將 PDF 檔進行摘要,並且翻譯成中文。
檔案的部分可以參考 Tesla 2023 Financial Report
# 匯入 & 安裝套件
# !pip install llama-parse
from llama_parse import LlamaParse
from dotenv import load_dotenv
load_dotenv()
# 指定檔案
pdf_file = "tesla.pdf"
# 指定解析格式 & 開始解析
parser = LlamaParse(result_type="markdown")
markdown_text = parser.load_data(pdf_file)
# 將解析結果存成 md 檔
with open("tesla.md", "w") as file:
file.write('\n'.join([ t.text for t in markdown_text]))
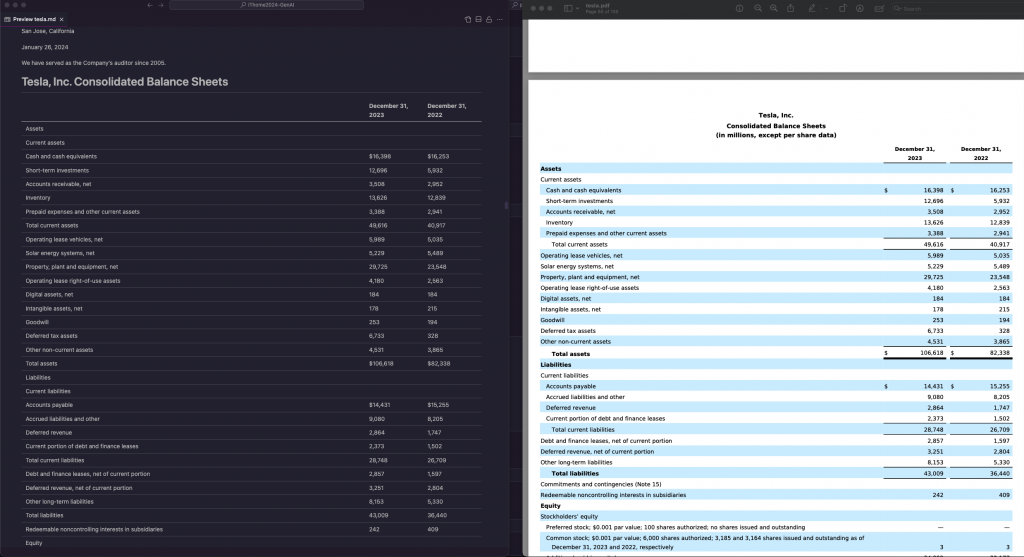
程式碼結果探討 🧐:
# 匯入套件 & 選擇模型
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain_text_splitters import RecursiveCharacterTextSplitter
import threading
from llama_parse import LlamaParse
from dotenv import load_dotenv
load_dotenv()
# 指定檔案 & 模型
pdf_file = "tesla.pdf"
llm = ChatOpenAI(model="gpt-4o", temperature=0)
# 指定解析格式 & 開始解析
parser = LlamaParse(result_type="markdown")
markdown_text = parser.load_data(pdf_file)
# 將結果存成字串
financial_report = '\n'.join([t.text for t in markdown_text])
# 切割文本
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
documents = text_splitter.create_documents([financial_report])
# map 函數
def map_summary(index, content, results, failed_indices):
try:
prompt = PromptTemplate.from_template("請將以下內容進行摘要: {text}")
chain = prompt | llm
summary = chain.invoke(content).content
results[index] = summary
except Exception as e:
failed_indices.append(index)
print(f"Error processing document {index}: {e}")
# 使用 map 函數進行平行運算
def process_documents(documents):
results = [None] * len(documents)
failed_indices = []
threads = []
for i, doc in enumerate(documents):
t = threading.Thread(target=map_summary, args=(i, doc, results, failed_indices))
t.start()
threads.append(t)
for t in threads:
t.join()
return results, failed_indices
# 取得 map 結果並且合併
results, failed_indices = process_documents(documents)
map_result = '\n'.join(results)
# reduce 函數
def reduce_summary(results):
prompt = PromptTemplate.from_template("請將以下內容進行摘要,並且串接成一個好閱讀的文章,不要分一堆段落: {text}")
chain = prompt | llm
reduced_summary = chain.invoke(results).content
return reduced_summary
# 輸出摘要結果
results = reduce_summary(map_result)
# 翻譯函數
def translation(content):
prompt = PromptTemplate.from_template("請將以下內容翻譯成繁體中文: {text}")
chain = prompt | llm
translation = chain.invoke(content).content
return translation
# 輸出翻譯結果
translation_result = translation(results)
print(translation_result)

程式碼結果探討 🧐:
今天實作了兩個工具,並都使用他們來進行了 Map-Reduce 的長文本摘要。這兩個都是我覺得很實用的工具,分享給大家~
為了慶祝自己日更撐完鐵人賽,買了一個 Samsung 的大螢幕送給自己,覺得好讚好值得😍

